


Subtitulado automático bilingüe: la idea es sencilla, la solución no tanto

![]()
Ofrecer al espectador subtitulado automático en directo no es una novedad, pero ¿se puede confiar lo suficiente en las tecnologías de inteligencia artificial para subtitular programas en dos idiomas? Carmen Pérez Cernuda, subdirectora del área de innovación y estrategia tecnológica en RTVE, arroja luz sobre esta temática.
Gracias a la amplia estructura territorial de RTVE, que dispone de un centro en cada una de las comunidades autónomas, es posible acercar al ciudadano las noticias que se producen en su entorno más próximo. Para ello, además de los espacios radiofónicos, TVE produce dos informativos diarios en cada uno de sus centros territoriales, que se emiten, simultáneamente, vía TDT mediante desconexiones territoriales, uno durante la mañana y otro en el inicio de la tarde.
Y es justamente esta simultaneidad la que complica el hacer un subtitulado de estos informativos por los métodos tradicionales con un presupuesto razonable. Por esta razón, históricamente se estaban subtitulando únicamente los informativos territoriales de Canarias, Cataluña y Madrid ya que, al ser Centros de Producción, existe en ellos un sistema de subtitulado manual o semiautomático utilizado para el resto de programas.
Primeros pasos en la automatización
La idea de automatizar el subtitulado surgió pronto, pero el reto no era baladí ya que, y como pequeño inciso para los menos familiarizados con el tema de la subtitulación, entre los que confieso que hasta hace poco también me encontraba yo, diré que existe una normativa estricta (UNE 153010/2012, así como el código de buenas prácticas del Centro Español del Subtitulado y la Audiodescripción, CESyA) que define de forma amplia y muy concreta multitud de parámetros como: densidad de subtitulado (en porcentaje respecto a todo lo hablado en el programa), retardo máximo entre la palabra y el texto, número máximo de letras por línea y de líneas, tiempo mínimo y máximo de permanencia en pantalla del texto, ubicación del subtítulo en la pantalla, etc. que se han de cumplir para garantizar la comprensión y el seguimiento de lo hablado.
Tras algunas pruebas de concepto y periodos de ajuste, se implantó para todos los informativos territoriales producidos en castellano un servicio de subtitulado automático (…) . Hoy en día, este es un servicio consolidado con unos niveles de calidad por encima incluso de lo esperado.
De ahí que no fuera hasta el año 2018, cuando el estado del arte de las tecnologías del habla y de la inteligencia artificial aplicada al procesamiento del lenguaje natural alcanzaron un grado de madurez que nos animara a aventurarnos en el subtitulado automático de programas informativos en directo con cierta garantía de éxito. Estas características de los programas añaden algunas dificultades a la automatización; tratarse de informativos implica que hay momentos en los que los hablantes no son profesionales y la toma de sonido no se realiza en las mejores condiciones ambientales, posición de micros, etc. Además, al ser en directo, implica que se dispone de un corto espacio de tiempo, apenas unos segundos, para la obtención y presentación en pantalla del subtítulo.
Tras algunas pruebas de concepto y periodos de ajuste, se implantó para todos los informativos territoriales producidos en castellano un servicio de subtitulado automático cuyos niveles de calidad eran al menos iguales al resto de sistemas de subtitulado utilizados hasta ese momento. Hoy en día, este es un servicio consolidado con unos niveles de calidad por encima incluso de lo esperado.
¿Y por qué no en centros bilingües?
Sin embargo, en ese momento la falta de modelos de lenguaje en otros idiomas hablados en España y la dificultad añadida de los cambios de idioma hicieron que no fuera posible ampliar el servicio a los informativos bilingües.
Tras algún intento fallido, por fin, en 2020 conseguimos, mediante concurso público, una empresa capaz de generar un servicio como el que demandábamos en castellano y los idiomas hablados en Navarra, P. Vasco, Baleares, C. Valenciana y Galicia, de forma que el subtítulo generado se escribiera en el mismo idioma en el que se estaba hablando.
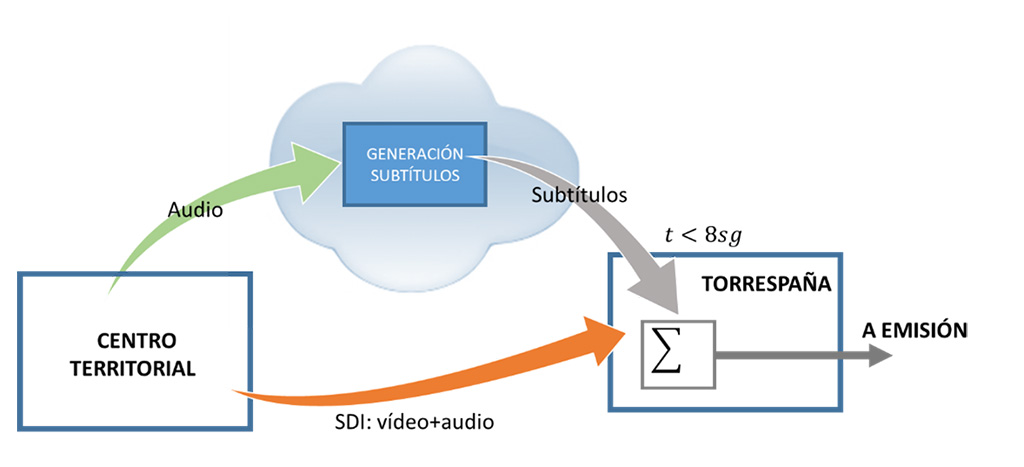
Al igual que en el caso de los informativos en castellano, se planteó desde el inicio que el servicio fuera en cloud, de forma que RTVE entrega la señal de audio del Informativo Territorial, en banda base a través del interfaz audio digital AES3, en el propio Centro donde se produce. La empresa encargada del servicio realiza el procesamiento necesario para la generación de los subtítulos de forma automática, en tiempo real y con reconocimiento del idioma hablado, apoyándose únicamente en el sonido en directo del programa, ya que no dispone de ayudas de sistemas de información previas, tal como guiones de las noticias, escaletas, etc.
Los subtítulos generados para todos los Centros se entregan en el CPP de Torrespaña (Madrid), en formato DVB sobre IP, para su incorporación en la trama TDT.
Los Centros Territoriales que utilizan este nuevo sistema son los de Comunidad Valenciana, Baleares, Galicia, País Vasco y Navarra, que se fueron incorporando escalonadamente, a razón de uno cada mes, desde febrero de 2021, una vez validados los resultados en cada caso mediante el correspondiente control de calidad.
Un sistema de alarmas, automatizado, permite tener conocimiento de cualquier error a lo largo de toda la cadena del servicio, el cual, además, en caso de mal funcionamiento, desconecta también el equipo de subtitulado. El servicio lo presta Aicox como empresa integradora aplicando la tecnología de Etiqmedia para el procesado y generación de subtítulos.
¿Cómo se genera el subtitulado bilingüe?
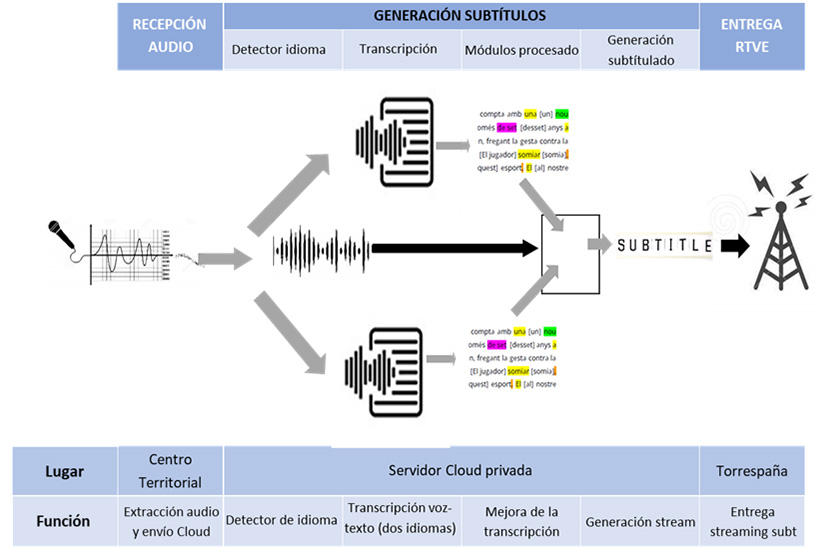
Para cada Centro, la solución dispone de dos sistemas de procesado funcionando en paralelo, uno para cada uno de los dos idiomas hablados en cada informativo. En este procesado se transcribe la voz a texto, se pasa por el diccionario, por el módulo de capitalización y puntuación, módulo de presentación de números y otros que aplican reglas para la mejora de algunos errores, siempre teniendo en cuenta que en todas estas fases hay que ser muy cuidadosos con los retardos que introducen al tratarse de subtitulado en directo. Aspirar a una muy buena calidad en cualquiera de ellos, significa añadir segundos que penalizan mucho la experiencia de usuario pudiendo llegar a incumplir la normativa.
Además, y como pieza fundamental del sistema, está el módulo de detección del idioma hablado, el cual, teniendo en cuenta las características acústicas y aplicando tecnologías basadas en redes neuronales, en solo cinco segundos tiene que decidir si el idioma en el que se está hablando es el A o el B, seleccionando así en qué lengua se presentan los subtítulos en cada momento. Igualmente, el hecho de ser “en directo” condiciona los parámetros que se pueden ajustar en el detector para mejorar su funcionamiento.
No todos los informativos bilingües son iguales…
Aunque la estructura del informativo territorial, en cuanto al contenido es igual en todos los centros (titulares, piezas editadas, algún directo, tiempo cultura y deportes), en lo que respecta al idioma no siguen ningún patrón común, lo que hace que los resultados del subtitulado automático no sean homogéneos.
Así, en algunos centros, como en Navarra y País Vasco, todo el informativo se realiza en castellano salvo un resumen de las noticias al final del mismo que se da en euskera; es más, en el caso de Navarra, se hace únicamente en el informativo de la tarde.
Una de nuestras preocupaciones es poder distinguir los errores achacables al detector de idioma y los que lo son al modelo de lenguaje
En otros, se habla prácticamente todo el informativo en la lengua de la Comunidad y solo se pasa al castellano cuando hay alguna intervención de personajes públicos, encuestas en la calle, etc. En el término medio estarían los informativos que, si bien el hilo conductor está en un único idioma, cada pieza o declaración puede estar en uno u otro según el autor de la misma.
También ocurre a menudo que, estando hablando en un idioma, algunas palabras se dicen en la otra lengua. Esto ocurre, aunque no únicamente, con nombres de entidades (organizaciones, localidades…), situación que naturalmente añade cierto grado de dificultad al reconocedor de idioma.
En el caso de Galicia, donde se habla el castellano con un fuerte acento en gallego, el detector de idioma, que trabaja con fonemas, tiene muchas dificultades para distinguir cuándo se produce un cambio de idioma, especialmente en el paso del gallego al castellano. Sin embargo, en Navarra, donde es el euskera el que se habla con marcado acento castellano, no se ha conseguido que el sistema reconozca el cambio de idioma. Para paliar la situación en este Centro concreto, dada su casuística, estamos trabajando para que el cambio de idioma se haga recurriendo a un módulo de detección de ráfagas.
 Seguimiento y parámetros de calidad
Seguimiento y parámetros de calidad

Otra pieza clave del proyecto es el exhaustivo control de calidad que se lleva a cabo y cuyos resultados sirven no solo para conocer la calidad de la solución sino para, detectando los puntos débiles, contribuir a la mejora del funcionamiento de la herramienta y por tanto de los niveles de calidad obtenidos.
Para ello, una empresa especializada, Aptent, que cuenta con expertos en todas las lenguas tratadas, analiza semanalmente dos fragmentos de cinco minutos de los informativos de cada Centro Territorial en los que se va variando tanto el día de la semana como el momento del informativo: al inicio, en medio o al final, realizando para cada fragmento un conjunto de medidas objetivas, recogidas en un informe semanal que incluye, además, los errores más destacados que han sido detectados.
Una de nuestras preocupaciones es poder distinguir los errores achacables al detector de idioma y los que lo son al modelo de lenguaje. Para conocer con exactitud la calidad del modelo de lenguaje se han establecido algunas premisas, como no tener en cuenta los cinco primeros segundos cada vez que hay un cambio de idioma (recordamos que es la ventana que se ha establecido para que el detector decida en qué lengua se habla y por tanto contiene errores). Por otro lado, tampoco se incluyen en el cálculo aquellas palabras afectadas cuando hay un cambio de idioma no detectado o añadido por el sistema.
Para conocer la calidad de la transcripción se utiliza, diferenciando para cada uno de los idiomas, la tasa de error por palabras (WER) que tiene en cuenta las palabras añadidas, eliminadas o transcritas erróneamente frente al total de palabras reales. También se hace un cálculo de la precisión, que además de los errores anteriores, tiene en cuenta los de puntuación y capitalización.
En lo que se refiere al funcionamiento del detector de idiomas, se tiene en cuenta los cambios no detectados y los que el sistema ha considerado un cambio de idioma sin que exista realmente frente a los cambios reales, analizando de forma separada los errores en el cambio de castellano al otro idioma y los contrarios.
También, sobre las mismas muestras, se hace un seguimiento del tiempo que tarda el subtitulado en aparecer en pantalla desde que se escuchó el audio.
 Algunos resultados
Algunos resultados

En general, hemos observado que los mejores resultados se obtienen cuando se analiza el inicio del informativo, los peores corresponden a los fragmentos del final del mismo, mientras que, cuando se analiza la parte central, los resultados varían mucho en función del contenido de estos fragmentos. Este es un comportamiento esperado, ya que el inicio del informativo se corresponde con la lectura por un profesional de un texto previamente redactado, por tanto, lenguaje estructurado y en un plató, es decir, con buena captación del audio, mientras que los fragmentos de la parte central suelen ser intervenciones con lenguaje natural, a veces desde la calle, por hablantes no profesionales y donde las condiciones acústicas son peores. La parte final del informativo normalmente corresponde al tiempo, deportes y cultura donde aparecen con mucha frecuencia nombres propios locales, con poca frecuencia de aparición, en los que estos sistemas son menos eficaces. Puede haber una diferencia de 2 a 5 puntos en la tasa de error WER entre el inicio y el final de los informativos.
Para el castellano se utiliza el mismo modelo de lenguaje, entrenado con miles de horas, para todas las comunidades sin que los resultados sean homogéneos. Los mejores resultados se obtienen en Navarra y P. Vasco, donde en más del 90% de las medidas realizadas, se obtiene un WER menor que 8% incluso en las partes mas complejas del informativo. La Comunidad Valenciana obtiene un WER por debajo del 10%, mientras que Galicia y Baleares tienen un comportamiento muy irregular y a veces, siempre hablando de los fragmentos analizados, hay tan pocas palabras en castellano, que no es posible hacer un cálculo de WER fiable en este idioma.
En cuanto al resto de idiomas, se obtienen estos resultados: euskera, el WER se mantiene por debajo del 15% en el 90% de las muestras. Comunidad Valenciana, WER menor que el 25% si es la parte final y el 15% si es en el inicio; Galicia, WER menor que el 20% en la parte final y el 15% en el resto; y Baleares, menor que el 20% en la parte final e inicial y muy irregular en el medio del informativo.
En lo referente a la precisión, la mayor cantidad de errores está en la capitalización y puntuación, fluctuando entre el 40 y el 50% así como en las palabras transcritas de forma incorrecta, entre el 25 y el 35%. A mucha distancia están las palabras perdidas, alrededor del 10%, siendo prácticamente insignificantes las palabras añadidas.
El detector de idioma tiene un comportamiento desigual en las distintas lenguas con resultados diferentes si el paso es de castellano a la lengua local, que si es en el sentido contrario, afectando a su funcionamiento también cuando, en un cambio de idioma, el fragmento que se habla en el idioma al que se ha cambiado es de pocos segundos.
En cuanto al tiempo de presentación en pantalla, cuyo máximo está en fijado en 8 segundos y, aunque en los inicios del proyecto estaba bastante próximo a esta cifra, ha ido mejorando y en la actualidad estamos entre los 5 y 6 segundos de media.
Qué podemos esperar
Los sistemas de redes neuronales aplicados a este tipo de casos de uso han supuesto una espectacular mejora en los resultados obtenidos respecto a otras tecnologías anteriores, sin embargo, tienen la contrapartida de que necesitan grandes cantidades de datos para su entrenamiento. Uno de los problemas más importantes en los idiomas tratados, a excepción del castellano, es que se dispone de muy pocos datos para poder entrenar. Por lo tanto, ya se esperaban resultados desiguales, según el idioma, ya que unos modelos de lenguaje podrían estar más o menos entrenados que otros, en función de trabajos o encargos ya prestados anteriormente en dichos idiomas, publicaciones de corpus abiertos, etc.
Por otro lado, y al tratarse de programas en directo, algunas fórmulas de mejora como la introducción de reglas posteriores a la transcripción solo se pueden aplicar cuando son muy sencillas porque, en caso contrario, penaliza el tiempo de entrega de los subtítulos.
Confiamos en que las capacidades computacionales continuarán incrementándose permitiendo introducir fórmulas más complejas para la mejora en la precisión y el tiempo de presentación en pantalla.
Al margen del avance de los modelos de lenguaje en los distintos idiomas, que se producirá, sin duda, con el incremento en el uso de sistemas de este tipo para diversas aplicaciones que dará lugar a que se disponga cada vez de más y más horas para entrenamiento, esperamos que tanto en la capitalización y puntuación con las nuevas tecnologías basadas en Transformers, como otras aplicadas a la detección de idioma, consigan un incremento apreciable en la calidad de los subtítulos obtenidos.
Por otro lado, confiamos en que las capacidades computacionales continuarán incrementándose permitiendo introducir fórmulas más complejas para la mejora en la precisión y el tiempo de presentación en pantalla.
Todos los motivos expuestos pero, sobre todo, el acercamiento de algunas asociaciones de personas sordas para felicitarnos porque por primera vez pueden seguir un informativo en su lengua materna, hacen que todo el esfuerzo invertido en este proyecto haya merecido la pena y nos aporta toda la motivación necesaria para continuar apostando por el mismo.
Carmen Pérez Cernuda
Subdirectora del área de innovación y estrategia tecnológica en RTVE

Cet article vous a plu ?
Abonnez-vous à notre Nourrir Et vous ne manquerez rien.
Autres articles connexes
 8 February 2023 RTVE y la UCLM impulsan una jornada centrada en innovación audiovisual
8 February 2023 RTVE y la UCLM impulsan una jornada centrada en innovación audiovisual 1 October 2020 Aicox lleva a cabo el subtitulado automático de los Centros de RTVE con informativos bilingües
1 October 2020 Aicox lleva a cabo el subtitulado automático de los Centros de RTVE con informativos bilingües 21 May 2019 RTVE adjudica a Aicox Soluciones el Lote 2 del sistema de monitorado y supervisión para su Red de Centros Emisores de RNE
21 May 2019 RTVE adjudica a Aicox Soluciones el Lote 2 del sistema de monitorado y supervisión para su Red de Centros Emisores de RNE 16 April 2019 Aicox suministra a RTVE más de trescientos receptores de satélite para América
16 April 2019 Aicox suministra a RTVE más de trescientos receptores de satélite para América 1 April 2019 RTVE renueva el sistema de ingesta masiva de la mano de Aicox Soluciones y Harmonic
1 April 2019 RTVE renueva el sistema de ingesta masiva de la mano de Aicox Soluciones y Harmonic 7 March 2019 Los Telediarios de TVE implantan la inteligencia artificial con Etiqmedia y Aicox
7 March 2019 Los Telediarios de TVE implantan la inteligencia artificial con Etiqmedia y Aicox 22 November 2018 Aicox, Etiqmedia, Harmonic y VSN analizan el impacto de la nube y la inteligencia artificial en el sector
22 November 2018 Aicox, Etiqmedia, Harmonic y VSN analizan el impacto de la nube y la inteligencia artificial en el sector 20 November 2018 Aicox organiza un seminario sobre gestión avanzada de contenidos, tráfico y producción en cloud
20 November 2018 Aicox organiza un seminario sobre gestión avanzada de contenidos, tráfico y producción en cloud 19 September 2018 RTVE renueva de la mano de Aicox Soluciones sus codificadores de emisión online con equipos Haivision
19 September 2018 RTVE renueva de la mano de Aicox Soluciones sus codificadores de emisión online con equipos Haivision 31 May 2018 RTVE congrega a la industria en un workshop sobre producción sobre entornos IP
31 May 2018 RTVE congrega a la industria en un workshop sobre producción sobre entornos IP 24 May 2018 Aicox Soluciones exhibió en BIT Audiovisual sus últimas propuestas de sus divisiones de satélite y broadcast
24 May 2018 Aicox Soluciones exhibió en BIT Audiovisual sus últimas propuestas de sus divisiones de satélite y broadcast 23 April 2018 Aicox Soluciones exhibirá en BIT Audiovisual sus soluciones para 4K, IP, cloud e inteligencia artificial
23 April 2018 Aicox Soluciones exhibirá en BIT Audiovisual sus soluciones para 4K, IP, cloud e inteligencia artificial